I’m intrigued by MAYA Design and their portfolio. They continue to craft novel, unique and useful environments, products and ideas, spinning off companies, both for profit and not, and publishing their research.
In particular, I like how MAYA’s Research practice takes the notion of “design” and applies it all the way “up”. Pervasive, ubiquitous computing is an ongoing design theme at MAYA. To achieve that, they explored designing information appliances. To power those appliances, they needed some sort of universal data representation. And to deliver all that data they investigated ways of storing, querying & delivering that universal data.
I was infatuated with MAYA’s idea of universal data (“u-forms”) back at the turn of the century. This paper (PDF) probably does the best job of explaining them. U-forms are simply name-value pairs along with a unique ID. Names are strings, values are byte sequences, the ID is some sort of UUID. That’s it. A “relation” is nothing more than a value with one or more UUIDs. Schema-free incidentally. Or not. Polymorphic schemas perhaps. You can refer to any set of name-values as whatever you want. (MAYA does go on to add a lot more structure around their use of u-forms–the VIA Repository if you’re Googling.)
Since the research papers were freely available but the code and tools were not, I spent many an evening playing around with the ideas and prototyping systems. Nothing came of that and I eventually moved on to other things.
But here in 2009 we have a cornucopia of u-form-esque systems at our fingertips. They’re sometimes called document databases with names like CouchDB, MongoDB or Cassandra and sometimes called key-value stores with names like Project Voldemort, Scalaris or Keyspace. There’s overlap there, what differentiates a doc db from a k-v store can be fuzzy. A pretty good overview can be found in this Anti-RDBMS article.
Although these db projects might be unproven and too new for widespread adoption, many of them are coming from companies with serious Big Data requirements and spawned from real pain & misery. Before doc databases turn hopelessly enterprise-y, what inspiration can be found from MAYA’s ongoing exploration of u-forms?
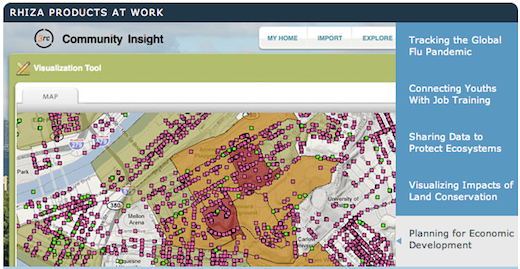
MAYA launched Rhiza Labs in 2008, “a software company that builds web-based applications to unify community information and improve decision-making in the public sector.” Community Insight and Comnunity Catalog both mention the ties to the VIA Repository and the Information Commons.
Insight, in particular, shows how the u-form idea can be exploited: “A user-friendly interface offers a wide range of mapping and charting capabilities, and enables you to obtain, input, and merge data sets in a variety of ways, create compelling presentations, publish your view of a situation and get feedback, and connect with experts and the people who use your data.” This sounds like a fun mash-up toolkit.
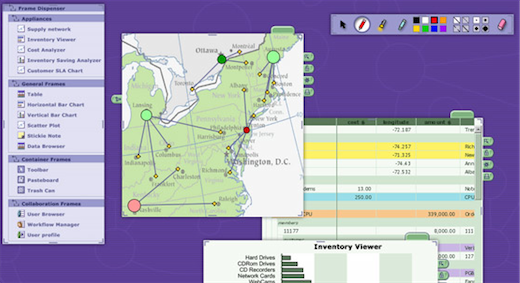
MAYA’s CoMotion (now part of General Dynamics) “helps people analyze information, share thoughts, and evaluate courses of action. The software provides a collaborative, interactive visualization environment that allows others to see what you think.”
Also built on a u-form foundation, “This directed graph of u-forms forms the basis for all data in the system, including visualized data, blueprints, as well as the frame locations and clipping states. Until the commercialization of CoMotion, no enterprise software products existed that allowed for this interaction. Prior, all systems either collaborated on the data itself, or only on the view of that data.” Watch the video to get a feel for it, link towards the center of the page.
The takeaway is that while document databases can (and will) excel as a back-end technology for large data sets they also have a exciting future for user interaction.
This entry was posted in Uncategorized. Bookmark the
permalink. Both comments and trackbacks are currently closed.
MAYA Design, U-forms and Today’s Document Databases
I’m intrigued by MAYA Design and their portfolio. They continue to craft novel, unique and useful environments, products and ideas, spinning off companies, both for profit and not, and publishing their research.
In particular, I like how MAYA’s Research practice takes the notion of “design” and applies it all the way “up”. Pervasive, ubiquitous computing is an ongoing design theme at MAYA. To achieve that, they explored designing information appliances. To power those appliances, they needed some sort of universal data representation. And to deliver all that data they investigated ways of storing, querying & delivering that universal data.
I was infatuated with MAYA’s idea of universal data (“u-forms”) back at the turn of the century. This paper (PDF) probably does the best job of explaining them. U-forms are simply name-value pairs along with a unique ID. Names are strings, values are byte sequences, the ID is some sort of UUID. That’s it. A “relation” is nothing more than a value with one or more UUIDs. Schema-free incidentally. Or not. Polymorphic schemas perhaps. You can refer to any set of name-values as whatever you want. (MAYA does go on to add a lot more structure around their use of u-forms–the VIA Repository if you’re Googling.)
Since the research papers were freely available but the code and tools were not, I spent many an evening playing around with the ideas and prototyping systems. Nothing came of that and I eventually moved on to other things.
But here in 2009 we have a cornucopia of u-form-esque systems at our fingertips. They’re sometimes called document databases with names like CouchDB, MongoDB or Cassandra and sometimes called key-value stores with names like Project Voldemort, Scalaris or Keyspace. There’s overlap there, what differentiates a doc db from a k-v store can be fuzzy. A pretty good overview can be found in this Anti-RDBMS article.
Although these db projects might be unproven and too new for widespread adoption, many of them are coming from companies with serious Big Data requirements and spawned from real pain & misery. Before doc databases turn hopelessly enterprise-y, what inspiration can be found from MAYA’s ongoing exploration of u-forms?
MAYA launched Rhiza Labs in 2008, “a software company that builds web-based applications to unify community information and improve decision-making in the public sector.” Community Insight and Comnunity Catalog both mention the ties to the VIA Repository and the Information Commons.
Insight, in particular, shows how the u-form idea can be exploited: “A user-friendly interface offers a wide range of mapping and charting capabilities, and enables you to obtain, input, and merge data sets in a variety of ways, create compelling presentations, publish your view of a situation and get feedback, and connect with experts and the people who use your data.” This sounds like a fun mash-up toolkit.
MAYA’s CoMotion (now part of General Dynamics) “helps people analyze information, share thoughts, and evaluate courses of action. The software provides a collaborative, interactive visualization environment that allows others to see what you think.”
Also built on a u-form foundation, “This directed graph of u-forms forms the basis for all data in the system, including visualized data, blueprints, as well as the frame locations and clipping states. Until the commercialization of CoMotion, no enterprise software products existed that allowed for this interaction. Prior, all systems either collaborated on the data itself, or only on the view of that data.” Watch the video to get a feel for it, link towards the center of the page.
The takeaway is that while document databases can (and will) excel as a back-end technology for large data sets they also have a exciting future for user interaction.